本电子书开源,欢迎 star 🌟,关注《LLM 应用开发实践笔记》
我的新书《LangChain编程从入门到实践》 已经开售!推荐正在学习AI应用开发的朋友购买阅读!

实现一个文档问答机器人
当前自有数据接入大模型有两种方式:微调模型和在 Prompt 上下文中带入知识
- prompt 上下文中带入知识,例如AI法律助手
- 缺点:效果较差,难以在要求比较高的垂直场景使用
- 优点:即开即用,应用落地速度非常快
- 微调(Fine-tuning)注入专业领域知识,例如中文法律通用模型由ChatGLM-6B LoRA 16-bit指令微调得到
- 缺点:减少了LLM编排的逻辑,直接调用即可
- 优点:成本和时间花费都比较高,而且需要定期进行调整以保持更新(法律文本还好一些)
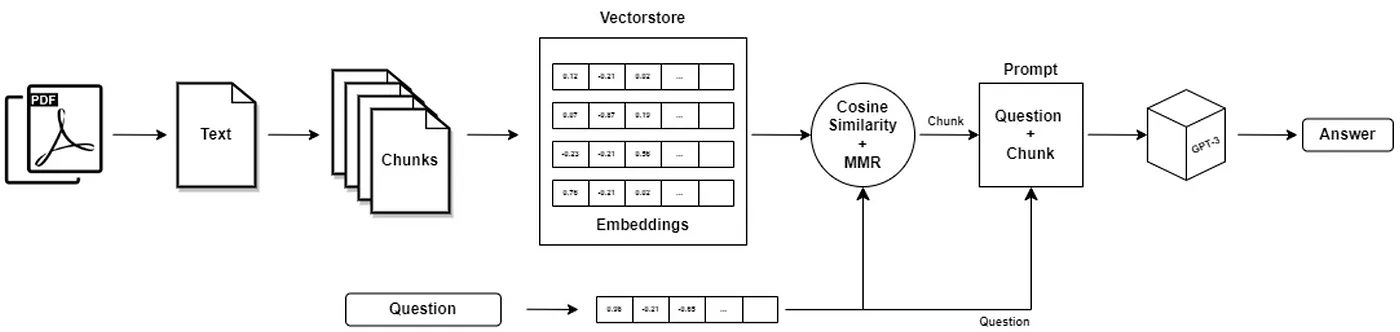
下面是一个文档问答机器人(Prompt 上下文中带入知识)的实现通用流程图

保险合同解读机器人
在人身保险产品信息库 查询已备案的保险合同原件,为PDF格式
合同文档分割
最简单的方案自然是,把保险条款按页码一页一页分块,如果一页内容也超了,那我们就半页半页分块。
最终实现
from langchain.chains import RetrievalQA
from langchain.llms import OpenAI
from langchain.document_loaders import PyPDFLoader,PDFMinerLoader,PDFPlumberLoader,PyMuPDFLoader
from langchain.text_splitter import CharacterTextSplitter
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import Chroma
def qa(file, query, chain_type, k):
# load document
loader = PyMuPDFLoader(file)
documents = loader.load()
# split the documents into chunks
text_splitter = CharacterTextSplitter(chunk_size=2000, chunk_overlap=0)
texts = text_splitter.split_documents(documents)
# select which embeddings we want to use
embeddings = OpenAIEmbeddings()
# create the vectorestore to use as the index
db = Chroma.from_documents(texts, embeddings)
# expose this index in a retriever interface
retriever = db.as_retriever(search_type="similarity", search_kwargs={"k": k})
# create a chain to answer questions
qa = RetrievalQA.from_chain_type(
llm=OpenAI(), chain_type=chain_type, retriever=retriever, return_source_documents=True)
result = qa({"query": query})
print(result['result'])
return result
def qa_result(prompt_text, select_chain_type, select_k):
result = qa(file="./test.pdf", query=prompt_text, chain_type=select_chain_type, k=select_k)
print(result)
if __name__ == "__main__":
import langchain
langchain.debug = True
qa_result("可以仔细讲讲免赔额吗", "map_reduce", 3)